Урок 2. Медиа, разметка, эмоджи и щепотка логирования
В этом уроке мы научим нашего бота:
- отправлять картинки, видео и аудио из файла, а также по айди;
- добавлять разметку на текст сообщений - полужирный, курсив, и
моноширинный текст; - отправлять пользователям эмоджи по уникальному имени
А также воспользуемся логированием, дабы посмотреть, что происходит под капотом.
Если вы собираетесь работать с отправкой эмоджи, и делать это не по их коду, например '\U0001F31A', а пользоваться наглядными названиями как :new_moon_with_face:, то необходимо установить библиотеку emoji, для этого воспользуемся командой pip install emoji (или командой python3.6 -m pip install emoji, если у вас установлено несколько интерпретаторов питона).
Зачем хранить айди файлов, которые мы отправляем?
Например, мы хотим добавить в нашего бота возможность отправлять картинки. Скорее всего, эти картинки будут отправлены неоднократно. Поэтому Телеграм даёт нам возможность отправлять файлы по айди. Вероятно, вы уже замечали, как это работает. Например, вы отправляете фото другу, оно отправляется пару секунд, а потом решаете отправить это же фото подруге, выбираете, жмете отправить, а оно тут же отправляется - это происходит потому, что ваш телеграм клиент запомнил, что вы уже отправляли это фото, поэтому в следующий раз шлёт его по айди. Боты могут то же самое (и даже лучше). Отправляя файл по айди мы в первую очередь ускоряем отправку сообщения пользователю, так как медиа уже загружено на сервер телеграм.
Итак, допустим, наш бот будет отправлять различные типы медиа. В этом уроке мы рассмотрим отправку изображений по одному, медиагруппами, отправку аудиосообщений, файлов, видео и видео в кружочке. Предполагая, что все файлы, отсылаемые нашим ботом, будут когда-либо отправлены пользователю, сделаем выгрузку данных заранее. Для того, чтобы не вносить данные в базу данных вручную, автоматизируем этот процесс. В данном случае нам подойдет база данных на движке SQLite. Для новичков скажу, что этот тип баз данных по умолчанию поддерживается языком Python (проверить это можно сделав в интерпретаторе import sqlite3). В своих проектах вы можете пользоваться любимыми ORM или писать чистые SQL запросы (вам всего доброго, хорошего настроения и здоровья). Мой выбор пал на SQLAlchemy. Так как работа с данной библиотекой - не тема наших уроков, я не буду углубляться в подробности и поверхностно расскажу, что происходит коде, относящемся к работе с базой данных (далее - БД). Напоминаю, что весь исходный код, продемонстрированный в уроке, доступен по ссылке. Отмечу, что база данных намерено представлена в максимально простом виде - в целях наглядности.
Ещё вам необходимо знать, что каждый бот видит разные айди у всех медиа файлов. По айди, который получил один бот, другой бот не сможет отправить ничего, а при попытке сделать это получит ошибку.
Наконец-то код!
Для начала создаем модель таблицы для нашей базы данных. Файл db_map.py:
from sqlalchemy import Column, Integer, String
from sqlalchemy.ext.declarative import declarative_base
Base = declarative_base()
class MediaIds(Base):
__tablename__ = 'Media ids'
id = Column(Integer, primary_key=True)
file_id = Column(String(255))
filename = Column(String(255))
Теперь загружаем в Телеграм файлы и сохраняем возвращаемые айди в базу данных. Для этого я написал небольшой скрипт, который доступен по ссылке. Если будете исполнять его на своём компьютере, можете обратить внимание на то самое логирование библиотеки aiogram.
Вот результат выполнения скрипта:
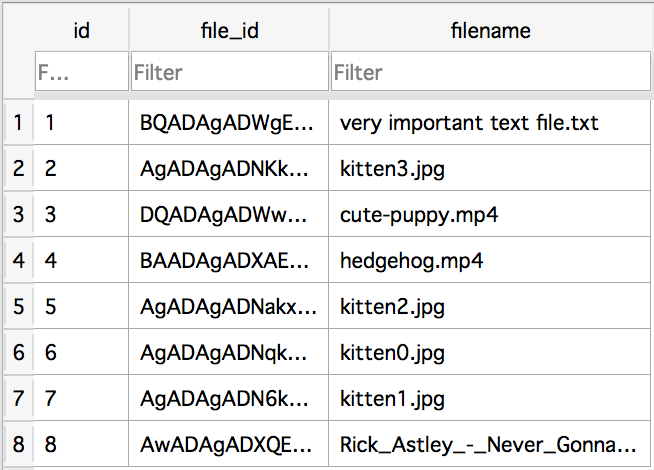
Представим, что в базе данных было ещё несколько полей, по которым вы в коде будете получать необходимые данные. Теперь переходим к основному коду бота. Так как создание логики запросов к БД - не тема этих уроков, допустим, что вы получили данные при старте программы и записали их в переменные (строки кода 17 - 26).
Создаем хэндлер команд /start и /help:
@dp.message_handler(commands=['start'])
async def process_start_command(message: types.Message):
await message.reply('Привет!\nИспользуй /help, '
'чтобы узнать список доступных команд!')
@dp.message_handler(commands=['help'])
async def process_help_command(message: types.Message):
msg = text(bold('Я могу ответить на следующие команды:'),
'/voice', '/photo', '/group', '/note', '/file, /testpre', sep='\n')
await message.reply(msg, parse_mode=ParseMode.MARKDOWN)
Обращу внимание читателя на то, что в ответе на команду /help мы воспользовались новыми методами: text и bold. Эти на первый взгляд простые функции сильно упрощают работу с генерацией текста. Первая склеивает в одно целое все передаваемые ей строчки, перемежая сепаратором (по умолчанию пробел, в таких случаях переменную sep вообще не нужно указывать), а вторая обрамляет входящую строчку метками для жирного текста (в данном примере используется разметка Markdown, поэтому это символы *. Для HTML теги будут другие). По аналогии работают методы italic, code и pre для Markdown и аналогичные для HTML. А чтобы Телеграм понял, что эти символы здесь не просто так, но обозначают разметку, мы явно указываем тип этой самой разметки: parse_mode=ParseMode.MARKDOWN. Напомню, что все необходимые импорты можно посмотреть по ссылке.
Затем добавляем обработчики всех остальных команд
О каждой по отдельности (за одно разберем эмоджи):
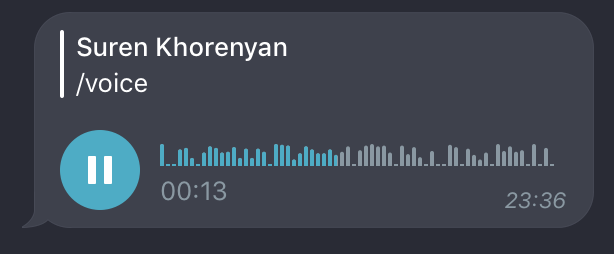
Отправка аудио + ответ на определенное сообщение:
@dp.message_handler(commands=['voice'])
async def process_voice_command(message: types.Message):
await bot.send_voice(message.from_user.id, VOICE,
reply_to_message_id=message.message_id)
Параметр reply_to_message_id отвечает за ответ на конкретное сообщение - айди можно указать любой доступный в этом чате (хоть просто поставить единицу). В данном случае берем айди сообщения, которое вызвало эту функцию.
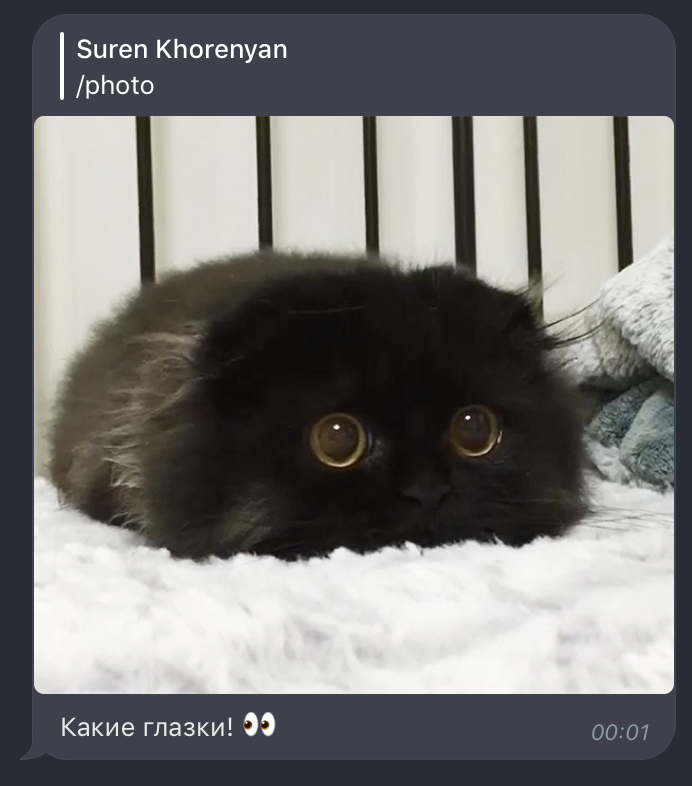
Отправка фото с комментарием + эмоджи:
@dp.message_handler(commands=['photo'])
async def process_photo_command(message: types.Message):
caption = 'Какие глазки! :eyes:'
await bot.send_photo(message.from_user.id, CAT_BIG_EYES,
caption=emojize(caption),
reply_to_message_id=message.message_id)
Тут мы дополнительно передаем данные в параметр caption, предварительно преобразовав текст, чтобы получить эмоджи из его кода. Теперь от простого переходим к более сложному.
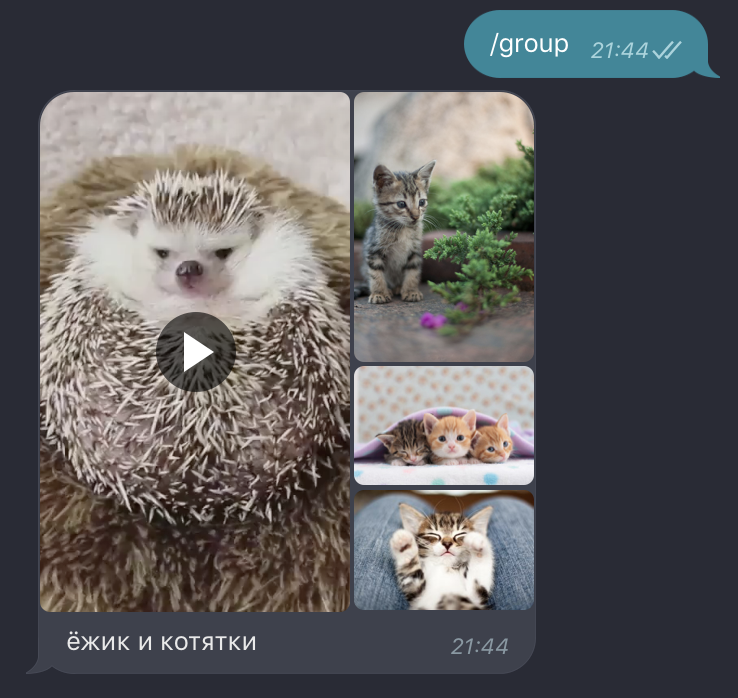
Отправка медиагруппы (где смешались кони, люди фото и видео):
@dp.message_handler(commands=['group'])
async def process_group_command(message: types.Message):
media = [InputMediaVideo(VIDEO, 'ёжик и котятки')]
for photo_id in KITTENS:
media.append(InputMediaPhoto(photo_id))
await bot.send_media_group(message.from_user.id, media)
Внимание! На момент публикации заметки при использовании релизной версии библиотеки невозможно отправить медиагруппу представленным выше способом из-за ошибки в коде. Недочёт исправлен в этом коммите. Версия 1.1, которая устанавливается через pip, уже несет в себе это исправление.
Итак, что же произошло в коде? Для начала создаем массив и кладем в него один элемент типа InputMediaVideo. Первый входной параметр - само видео (в данном случае айди), а второй элемент - caption (его передавать не обязательно). Дальше в цикле заполняем массив элементами типа InputMediaPhoto. Их создаем без подписи, тем самым делаем так, что всей медиагруппе принадлежит комментарий, оставленный к первому медиа. Затем просто в нужный метод передаем массив элементов. Можно, конечно, ещё было передать сразу медиагруппу, сделав MediaGroup(media), но так как библиотека делает это сама, то какой смысл писать лишний код и делать лишний импорт?
Отправка видеозаметки (видео в кружочке):
@dp.message_handler(commands=['note'])
async def process_note_command(message: types.Message):
user_id = message.from_user.id
await bot.send_chat_action(user_id, ChatActions.RECORD_VIDEO_NOTE)
await asyncio.sleep(1) # конвертируем видео и отправляем его пользователю
await bot.send_video_note(message.from_user.id, VIDEO_NOTE)
Представим, что вы собираетесь отправить пользователю видео в кружочке, которое ещё ни разу не было отправлено. Так как загрузка займет какое-то время, можно передать пользователю информацию, что бот получил команду и в данный момент обрабатывает её. Для этого существует метод sendChatAction. После отправки этого уведомления, приложение будет показывать пользователю, что бот сейчас что-то делает. Телеграм уберет этот статус как только бот отправит следующее сообщение, но не позже, чем через пять секунд. Для имитации каких-то действий со стороны бота просто выставляем ожидание в секунду.

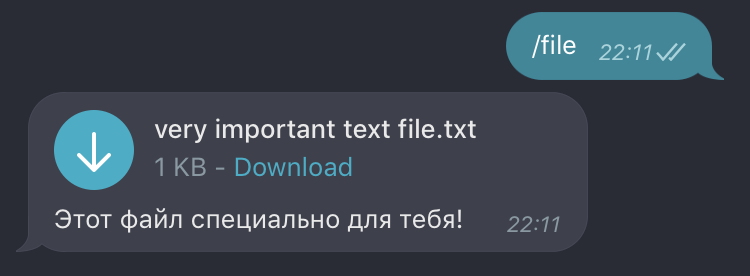
Отправка файла:
@dp.message_handler(commands=['file'])
async def process_file_command(message: types.Message):
user_id = message.from_user.id
await bot.send_chat_action(user_id, ChatActions.UPLOAD_DOCUMENT)
await asyncio.sleep(1) # скачиваем файл и отправляем его пользователю
await bot.send_document(user_id, TEXT_FILE,
caption='Этот файл специально для тебя!')
Тут как и в предыдущем примере предполагаем, что файл нужно ещё откуда-то достать или, может, сгенерировать, поэтому снова отправляем chatAction, выжидаем драматичную паузу и отправляем сам файл.
Преформатированный текст:
@dp.message_handler(commands=['testpre'])
async def process_testpre_command(message: types.Message):
message_text = pre(emojize('''@dp.message_handler(commands=['testpre'])
async def process_testpre_command(message: types.Message):
message_text = pre(emojize('Ха! Не в этот раз :smirk:'))
await bot.send_message(message.from_user.id, message_text)'''))
await bot.send_message(message.from_user.id, message_text,
parse_mode=ParseMode.MARKDOWN)
Так как разметка тут немного шалит, приложу ещё и скриншот кода с более понятной подсветкой синтаксиса:
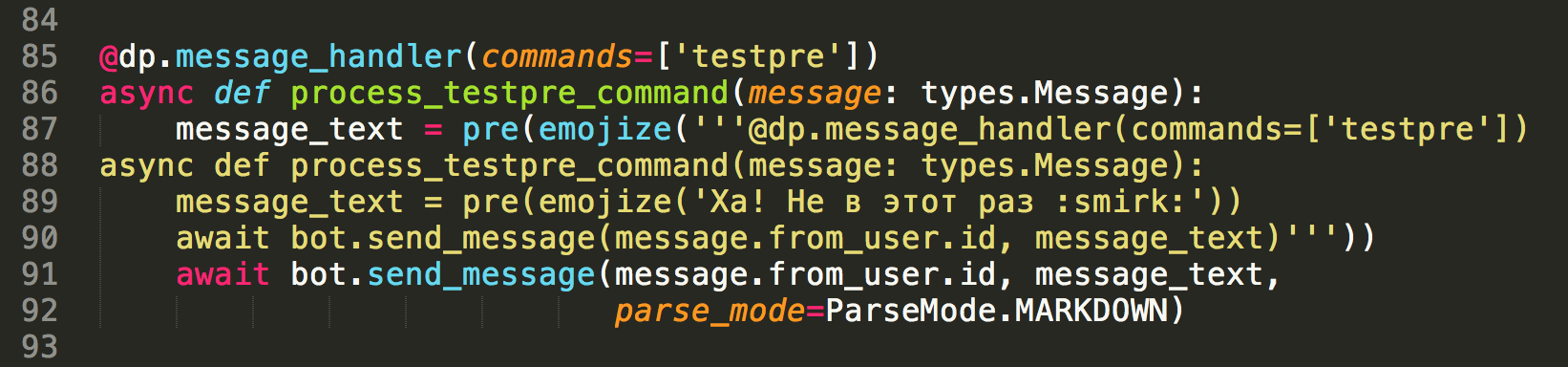 Тут мы отправляем преформатированный текст. Обычно такая разметка необходима при отправке блоков кода. По сути, это тот же моноширинный шрифт как и при использовании
Тут мы отправляем преформатированный текст. Обычно такая разметка необходима при отправке блоков кода. По сути, это тот же моноширинный шрифт как и при использовании code (рассмотрим его ниже), однако pre работает для многострочных вставок и автоматически отделяется переносом строки до и после. В качестве примера отправим данную же функцию с её хэндлером. Получаем такой результат:

Ну и напоследок немного улучшим знания, полученные в предыдущем уроке и закрепим их на деле:
Оставим для нерадивого пользователя пару хэндлеров для нежданных сообщений:
@dp.message_handler()
async def echo_message(msg: types.Message):
await bot.send_message(msg.from_user.id, msg.text)
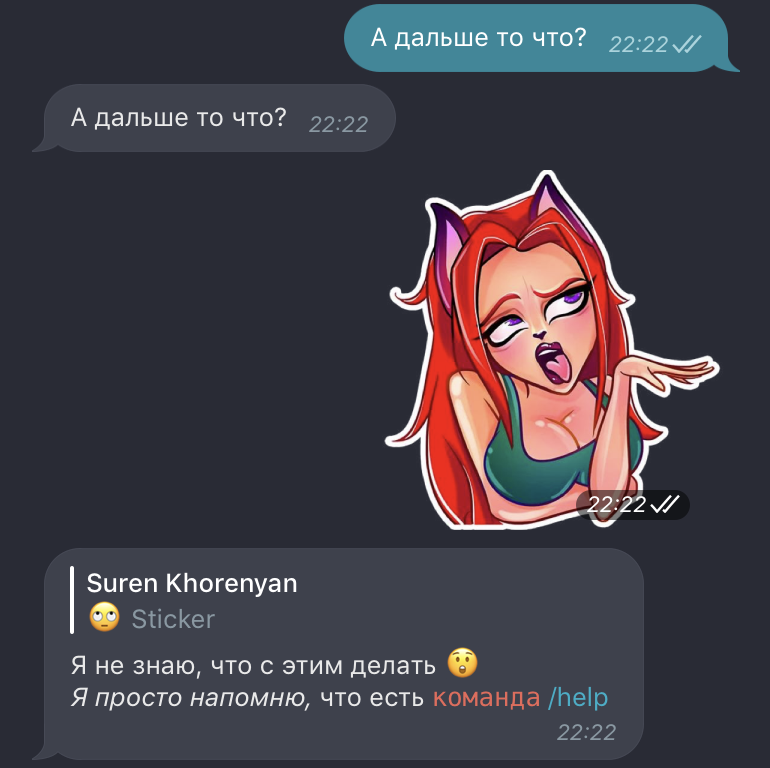
@dp.message_handler(content_types=ContentType.ANY)
async def unknown_message(msg: types.Message):
message_text = text(emojize('Я не знаю, что с этим делать :astonished:'),
italic('\nЯ просто напомню,'), 'что есть',
code('команда'), '/help')
await msg.reply(message_text, parse_mode=ParseMode.MARKDOWN)
И если первый должен быть понятен ещё с первого урока, то о втором расскажу поподробнее:
Так как по умолчанию в пустой хэндлер прилетают только текстовые сообщения, то наш бот будет игнорировать все остальные типы сообщений. Специально для этого мы создаем "уловитель" этих самых "всех остальных типов" сообщений, передавая content_types=ContentType.ANY. Обращу внимание читателя на то, что данная библиотека работает так, что сообщение передается в первый подходящий по условиям message_handler, поэтому необходимо соблюдать логический порядок. И именно по этой причине нельзя ставить хэндлер команд выше хэндлера текстовых сообщений — из-за того, что команды - это тоже текстовые сообщения, в вашей программе будет нарушена логика.
Домашнее задание
В качестве домашнего задания предлагаю вам поэкспериментировать и выполнить следующие действия:
- отправить видео;
- отправить геолокацию;
- отправить аудиофайл (музыку);
- отправить группу из фото (видео опционально), где у каждого элемента будет свой уникальный
caption; - отправить фото по ссылке со внешнего источника - просто передайте не файл, не айди, а ссылку на файл;
- поставить хэндлер текста выше хэндлера команд, посмотреть, что будет.